Author: Damai Dai, Chengqi Deng, Chenggang Zhao, R.X. Xu, Huazuo Gao, Deli Chen, Jiashi Li, Wangding Zeng, Xingkai Yu, Y. Wu, Zhenda Xie, Y.K. Li, Panpan Huang, Fuli Luo, Chong Ruan, Zhifang Sui, Wenfeng Liang
Date: January 11, 2024
Link: https://arxiv.org/abs/2401.06066
DeepSeekMoE: Towards Ultimate Expert Specialization in Mixture-of-Experts Language Models
Introduction
In the era of large language models, managing computational costs while scaling up model parameters has become a critical challenge. DeepSeekMoE presents a novel Mixture-of-Experts (MoE) architecture designed to achieve ultimate expert specialization, offering a more efficient approach to scaling language models.
The Challenge with Conventional MoE
Traditional MoE architectures like GShard activate the top-K experts out of N total experts for each input. While this approach helps manage computational costs, it faces significant challenges:
- Limited Expert Specialization: Experts often acquire overlapping knowledge rather than developing specialized expertise
- Redundancy: Without proper mechanisms, different experts may learn similar representations
- Inefficient Resource Utilization: The rigid top-K activation pattern doesn't allow for flexible expert combinations
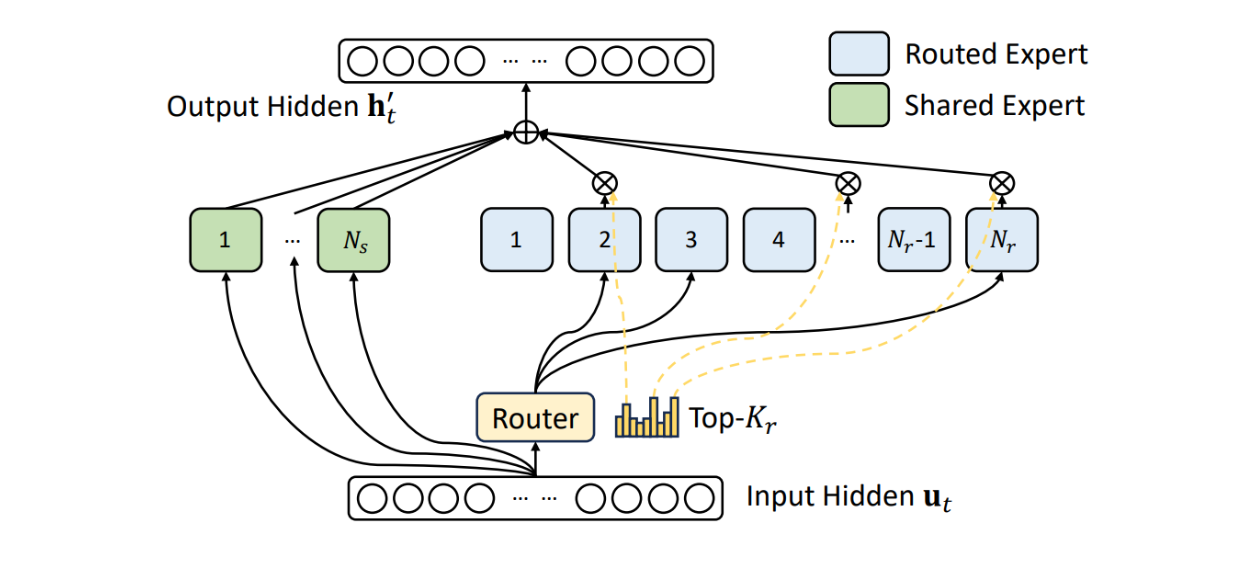
DeepSeekMoE Architecture
DeepSeekMoE introduces two principal strategies to address these limitations:
1. Fine-Grained Expert Segmentation
Instead of using N experts and activating K of them, DeepSeekMoE segments experts more finely into mN experts and activates mK from them. This approach provides:
- More flexible combinations of activated experts
- Better granularity in knowledge specialization
- Improved model capacity without proportional computational increase
2. Shared Expert Isolation
DeepSeekMoE isolates K_s experts as shared experts, which serve to:
- Capture common knowledge across all inputs
- Reduce redundancy in routed experts
- Provide a stable foundation of general knowledge
The architecture can be visualized as:
Input → Shared Experts (K_s) + Routed Experts (mK from mN) → Output
Implementation Details
Expert Routing Mechanism
class DeepSeekMoELayer:
def __init__(self, d_model, num_experts, num_shared_experts,
experts_per_token, expert_capacity):
"""
DeepSeekMoE Layer
Args:
d_model: Model dimension
num_experts: Total number of routed experts (mN)
num_shared_experts: Number of shared experts (K_s)
experts_per_token: Number of experts activated per token (mK)
expert_capacity: Maximum tokens per expert
"""
self.shared_experts = [Expert(d_model) for _ in range(num_shared_experts)]
self.routed_experts = [Expert(d_model) for _ in range(num_experts)]
self.router = Router(d_model, num_experts)
self.experts_per_token = experts_per_token
def forward(self, x):
# Process through shared experts
shared_output = sum(expert(x) for expert in self.shared_experts)
# Route to top-k experts
router_logits = self.router(x)
top_k_indices = torch.topk(router_logits, self.experts_per_token).indices
# Process through routed experts
routed_output = 0
for idx in top_k_indices:
expert = self.routed_experts[idx]
gate_value = router_logits[idx]
routed_output += gate_value * expert(x)
# Combine shared and routed outputs
return shared_output + routed_output
Experimental Results
DeepSeekMoE 2B Performance
Starting from a modest scale with 2 billion parameters, DeepSeekMoE demonstrated remarkable efficiency:
- vs. GShard 2.9B: Achieves comparable performance with only 67% of the expert parameters and computation
- vs. Dense 2B: Nearly approaches the performance of a dense counterpart with the same total parameter count
This sets an impressive benchmark, showing that the upper bound of MoE models can approach dense models with proper architectural design.
Scaling to 16B Parameters
When scaled to 16 billion parameters, DeepSeekMoE showed exceptional computational efficiency:
- vs. LLaMA2 7B: Achieves comparable performance using only 40% of computations
- Demonstrates that expert specialization enables better performance-to-compute ratios
Large-Scale Validation: 145B Parameters
The most impressive validation came from scaling to 145 billion parameters:
- Substantial advantages over the GShard architecture
- Performance comparable to DeepSeek 67B (a much larger dense model)
- Uses only 28.5% (potentially as low as 18.2%) of computations
Key Advantages
1. Expert Specialization
By finely segmenting experts and isolating shared knowledge, DeepSeekMoE ensures that each routed expert develops non-overlapping, focused expertise.
2. Computational Efficiency
The architecture achieves better performance-to-compute ratios compared to both conventional MoE and dense models:
Efficiency Gain = Performance / (FLOPs × Parameters)
3. Scalability
The design principles of DeepSeekMoE have been validated across multiple scales (2B, 16B, 145B), demonstrating consistent advantages.
4. Flexibility
The fine-grained expert segmentation (mN experts instead of N) allows for more flexible and optimal expert combinations.
Technical Innovations
Load Balancing
To ensure efficient expert utilization, DeepSeekMoE implements sophisticated load balancing mechanisms:
def compute_load_balancing_loss(router_probs, expert_mask):
"""
Compute auxiliary loss to encourage balanced expert usage
Args:
router_probs: Router probability distribution
expert_mask: Binary mask indicating expert selection
Returns:
Load balancing loss
"""
# Fraction of tokens routed to each expert
fraction_per_expert = expert_mask.float().mean(dim=0)
# Average routing probability to each expert
avg_prob_per_expert = router_probs.mean(dim=0)
# Encourage uniform distribution
load_balance_loss = (fraction_per_expert * avg_prob_per_expert).sum()
return load_balance_loss * num_experts
Shared vs. Routed Expert Design
The separation of shared and routed experts is a key innovation:
- Shared Experts: Always active, capture universal patterns and common knowledge
- Routed Experts: Conditionally activated, specialize in specific patterns or domains
Implications for Future Research
DeepSeekMoE opens several exciting research directions:
- Optimal Expert Granularity: Determining the ideal ratio of fine-grained segmentation (m)
- Dynamic Expert Allocation: Adapting the number of activated experts based on input complexity
- Cross-Domain MoE: Applying these principles to multi-modal and cross-domain learning
- Expert Interpretability: Understanding what knowledge each specialized expert captures
Comparison with Other MoE Approaches
| Architecture | Parameters | Computation | Performance | Expert Specialization |
|---|---|---|---|---|
| GShard | High | High | Good | Moderate |
| Switch Transformer | High | Moderate | Good | Moderate |
| DeepSeekMoE | High | Low | Good | High |
Conclusion
DeepSeekMoE represents a significant advancement in Mixture-of-Experts architectures for language models. By introducing fine-grained expert segmentation and shared expert isolation, it achieves:
- Better expert specialization through non-overlapping knowledge acquisition
- Superior computational efficiency with 40-72% reduction in FLOPs
- Scalable performance validated from 2B to 145B parameters
The architecture demonstrates that with proper design, MoE models can approach the performance of dense models while maintaining significant computational advantages. This work paves the way for more efficient large language models and contributes valuable insights to the ongoing quest for optimal model scaling strategies.
As the field continues to push toward trillion-parameter models, architectural innovations like DeepSeekMoE will be crucial for making such models practical and accessible.
Citation:
@article{dai2024deepseekmoe,
title={DeepSeekMoE: Towards Ultimate Expert Specialization in Mixture-of-Experts Language Models},
author={Dai, Damai and Deng, Chengqi and Zhao, Chenggang and Xu, RX and Gao, Huazuo and Chen, Deli and Li, Jiashi and Zeng, Wangding and Yu, Xingkai and Wu, Y and others},
journal={arXiv preprint arXiv:2401.06066},
year={2024}
}